4 Data Viz with ggplot2, basics
4.2 The ggplot2 Package
In writing, complex ideas are communicated by using relatively simple grammatical rules. For graphics, the same concept holds true, and
has given rise to the concept of the Grammar of Graphics. ggplot2 is an implementation of the Grammar of Graphics in R. In practical terms, it means that you have control of all aspects of a statistical graphic. To continue our writing analogy: We can think of building a sentence by combining different word classes, such as nouns and their modifying adjectives, or verbs and their modifying adverbs. Similarly, we can think of building graphics (see web-site by combining different layers. The main layer classes are:
- Data describes the data set being plotted.
- Geometries (geom) describe the actual plotting elements, such as lines, bars and boxes.
- Aesthetics (aes) describe the way a data point will look, such as colour, size and shape.
- Statistics describe calculated summaries, such as regression lines, binning, and descriptive statistics.
- Coordinates describe the coordinate system on which the data will be plotted.
- Facets describe how the data should be sub-setted for plotting.
- Themes describe the non-data ink.
The main plotting function in ggplot2 is ggplot(). A key aspect of layering is understanding that ggplot2 plots are themselves R objects. That means they can be assigned to a unique object name, just like vectors and data frames. The first step in creating a ggplot is to create a data layer.
4.3 The Data Layer
Every ggplot2 plot must consist of a data layer, which takes the generic form:
or simply:
By establishing the base data layer, we specify the data frame of interest, and the specific variables to be plotted as aesthetics (see below). Notice that the aesthetics argument does not follow classical argument form for R functions, aes =, but instead appears as a nested function, aes(), having its own arguments.
# Mapping two aesthetics in the data layer
mpg.wt <- ggplot(mtcars, aes(x = wt, y = mpg))
mpg.wt
# Mapping a single aesthetic in the data layer
mpg <- ggplot(mtcars, aes(mpg))
mpg| Aesthetic | Description |
|---|---|
x |
Map onto the x axis |
y |
Map onto the y axis |
color/colour or fill
|
Map onto the colour or fill |
size |
Map onto the size |
alpha |
Map onto the alpha-blending |
linetype |
Map onto the line style |
shape |
Map onto the shape |
4.4 The Geom Layer
An object consisting of only a data layer (with associated aesthetics) does not produce a plot. A grammatically complete graphic requires a geometry layer, specifying what form the data should take. To add a new layer, a + sign is added and the specific geometry is specified with a geom_ function and any necessary arguments. In our first plots, geom_point() is used to make a scatter plot of two variables using the default settings and geom_histogram() is used to make a histogram of a single variable.
Table (#tab:ggplot2-geometries): ggplot2 geoms.
| Geom | Description |
|---|---|
geom_bar() |
Draw a bar plot. |
geom_boxplot() |
Draw a bot plot. |
geom_density() |
Draw a density estimate. |
geom_histogram() |
Histogram. |
geom_jitter() |
Add jittered points. |
geom_line() |
Connect observations in order of another value. |
geom_path() |
Connect observations in their original order. |
geom_point() |
Add points, e.g. scatterplots and dot plots. |
geom_smooth() |
Add a smoothed line. |
geom_text() |
Text annotations. |
geom_hline() |
Horizontal lines |
geom_vline() |
Vertical lines. |
geom_errorbar() |
Vertical errorbars |
geom_errorbarh() |
horizontal errorbars |
geom_ribbon() |
Shaded ribbon. |
# A scatter plot of two variables
mpg.wt + geom_point()
Figure 4.1: Some examples of simple ggplots.
# A histogram of a single variable.
mpg + geom_histogram()
#> `stat_bin()` using `bins = 30`. Pick better value with
#> `binwidth`.
Figure 4.2: Some examples of simple ggplots.
We can use arguments to specify the particulars of each layer. Here, we call the aes() function once again inside geom_histogram() to specify exactly what should be mapped to the y axis. In this case we specify that the density should be plotted on the y axis, and not the default count. The reference to density is surrounded by .. because it is a variable generated by geom\_histogram(). This means that density is an internal variable, accessed using the .. notation to avoid potential confusion with variables in the original data frame.
# A scatter plot of two variables
mpg.wt + geom_point(colour = "blue",
shape = "X",
size = 4)
Figure 4.3: Some examples of simple ggplots.
# A histogram of a single variable, showing density.
mpg + geom_histogram(aes(y = ..density..),
binwidth = 1,
fill = "#C42126")
Figure 4.4: Some examples of simple ggplots.
4.5 The Aesthetics Layer
The scale_ functions map data to aesthetics, including position, colour, size, shape and line type. Default scales are used when needed, but you have full control over all aesthetics of a plot with the scale_ functions. There are four categories of scales - position, colour, manual-discrete and identity. We will look at each type using examples from the mtcars data sets.
4.5.1 Position for mapping continuous, categorical and date-time vari- ables onto the appropriate axes.
“Position” determines how plotting elements are arranged in the plotting space. We have encountered this with jittered scatter plots. Consider the example below with bar plots.
Table (#tab:positions): position variants.
position = |
|---|
| “dodge” |
| “fill” |
| “identity” |
| “stack” |
| “jitter” |
| “jitterdodge” |
| “nudge” |
cyl.am <- ggplot(mtcars, aes(x=factor(cyl), fill=factor(am))) # The data layer:
cyl.am + geom_bar() # Default position = "stack"
cyl.am + geom_bar(position="fill") # Position fill
cyl.am + geom_bar(position="dodge") # Position dodge
Each position argument in the table above can also be set using a function in the form position\_X(), where X is the position argument. We will see an example on this later on when we look at summary statistics. “Position” also specifically refers to the position scales, i.e. the axes.
4.5.2 Colour for mapping continuous, categorical variable to colours.
# adjusted discrete and continuous axes:
cyl.am +
geom_bar() +
scale_x_discrete("Cylinders", labels = c("4" = "Four","6" = "Six", "8" = "Eight")) +
scale_y_continuous(limits = c(0, 40), breaks = seq(0,40,5), expand = c(0,0)) 
mpg.wt + geom_point() # Default x axis
mpg.wt + geom_point() + scale_x_reverse() # reversed x axis
Table (#tab:positionscale): Common scale functions for using the position argument. All scales available with scale_y.
| Position scale functions |
|---|
scale_x_continuous() |
scale_x_log10() |
scale_x_reverse() |
scale_x_sqrt() |
scale_x_discrete() |
scale_x_date() |
scale_x_datetime() |
4.5.3 Colour for mapping continuous, categorical variable to colours.
Table (#tab:ggplot2-aesthetics-1): scale\_colour variants.
| Function Family | Description | Specific functions |
|---|---|---|
scale_color_brewer() |
Sequential, diverging and qualitative colour scales from RColorBrewer. |
scale_color_brewer(), scale_fill_brewer()
|
scale_colour_gradient() |
Smooth gradient between two colours. |
scale_color_continuous() scale_colour_continuous() scale_color_gradient() scale_colour_gradient() scale_fill_continuous() scale_fill_gradient()
|
scale_colour_gradient2() |
Diverging colour gradient. |
scale_color_gradient2(), scale_fill_gradient2()
|
scale_colour_gradientn() |
Smooth colour gradient between n colours. |
scale_color_gradientn(), scale_fill_gradientn()
|
scale_colour_grey() |
Sequential grey colour scale. |
scale_color_grey(), scale_fill_grey()
|
scale_colour_hue() |
Qualitative colour scale with evenly spaced hues. |
scale_color_discrete(), scale_color_hue(), scale_colour_discrete(), scale_fill_discrete(), scale_fill_hue()
|
# Establish the data and geom layers with the factor cyl as a colour aesthetic
mpg.wt <- ggplot(mtcars, aes(x = wt, y = mpg, col = factor(cyl))) + geom_point()
# Default colour
mpg.wt # equivalent to: mpg.wt + scale_color_hue()
# With RColourBrewer
mpg.wt + scale_colour_brewer() # Defaults to type="seq"
# An alternative RColourBrewer palette
mpg.wt + scale_colour_brewer(type="qual", palette="Dark2")
4.5.4 Manual
for mapping categorical variables to size, linetype, shape, or colour (plus corresponding legend).
Table (#tab:scale_manual-variants): scale_manual() variants.
Scale_manual() |
|---|
scale_alpha_manual |
scale_color_manual |
scale_colour_manual |
scale_fill_manual |
scale_linetype_manual |
scale_shape_manual |
scale_size_manual |
Manual scales allow you to create your own discrete scales. In the following example, the variable cyl is mapped to the colour aesthetic, so we use scale\_colour\_manual() to adjust the scale as we would like. Table @ref(tab:scale_manual-variants) lists the available functions.
mpg.wt 
mpg.wt + scale_colour_manual(limits = c(6, 8, 4),
breaks = c(8, 4, 6),
values = c("pink", "light blue", "yellow"))
#> Warning: Continuous limits supplied to discrete scale.
#> Did you mean `limits = factor(...)` or `scale_*_continuous()`?
4.5.5 Identity for plotting variables directly to an aesthetic instead of mapping.
Using the identity of a variable means taking its values directly, without using them as a scale, as shown in the following example. The functions available for this purpose are listed in table @ref(tab:scale_identity-variants).
Table (#tab:scale_identity-variants): scale\_identity() variants.
Scale_identity() |
|---|
scale_alpha_identity |
scale_color_identity |
scale_colour_identity |
scale_fill_identity |
scale_linetype_identity |
scale_shape_identity |
scale_size_identity |
# Plotting cyl scaled to size:
ggplot(mtcars, aes(x = wt, y = mpg, size = cyl)) + geom_point()
# However, cyl is not a continuous scale. It is a discrete variable with three categories:
# levels(factor(mtcars$cyl))
# Plotting cyl as point size
ggplot(mtcars, aes(wt, mpg, size = cyl)) + geom_point() + scale_size_identity()
4.6 The Statistics Layer
Statistics can be specified on their own layer using the stat_*() functions.
The geom_histogram() function, seen above, contain an argument for the binwidth, which is a statistic specific to geom_histogram() and is automatically calculated.
The statistics layer is useful for looking at calculations, such as regression with stat_smooth(). The default smoothing method is Loess for n < 1000, but because it is computationally intense for larger data sets, stat_smooth() defaults to a generalized additive model (gam) for larger data sets. The regression method can be specified with the method argument ("lm", "glm", "gam", "loess", and "rlm") as shown below. The line represents our fitted model and the grey shaded areas represent the 95% confidence intervals. Take note that the regression line (stat_smooth()) can be plotted without the corresponding points (geom_point()).
mpg.wt <- ggplot(mtcars, aes(x = mpg, y = wt))
mpg.wt + stat_smooth()
#> `geom_smooth()` using method = 'loess' and formula 'y ~ x'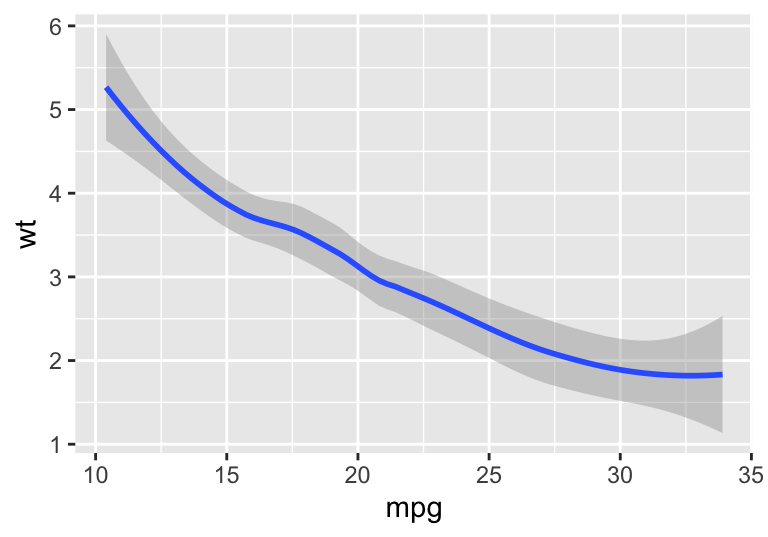
Figure 4.5: An example of ggplot’s stat_smooth() function.
mpg.wt + stat_smooth(method = "lm")
#> `geom_smooth()` using formula 'y ~ x'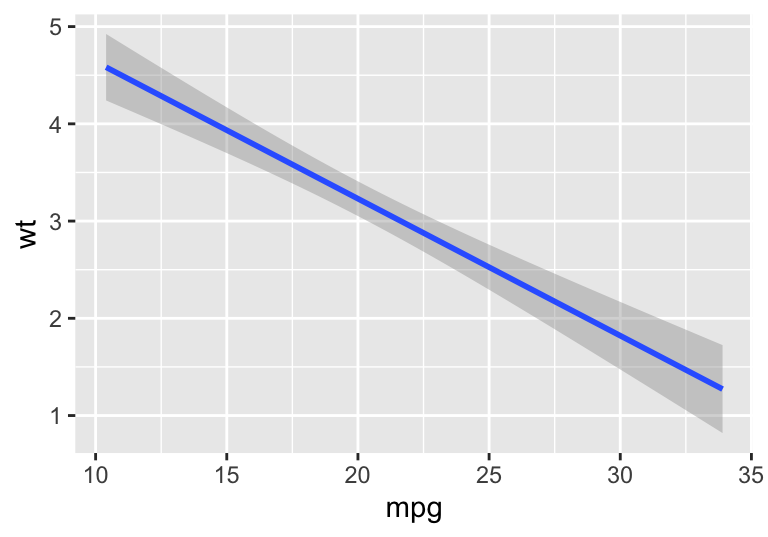
Figure 4.6: An example of ggplot’s stat_smooth() function.
The stat_summary() function is particularly useful for plotting simple summary statistics. This is demonstrated with a dot plot of the mean car weights according to cylinders and transmission type. The argument mean_sdl plots error bars for the standard deviation, but by default for 2 units, so we use mult = 1 to obtain 1 SD. The argument mean_cl_normal plots error bars for the 95% confidence interval.
# properly set factor variables:
mtcars$cyl <- as.factor(mtcars$cyl)
mtcars$am <- as.factor(mtcars$am)
# Set a specific value for the dodge position, here we combine dodge and jitter:
dodge.posn <- position_jitterdodge(jitter.width = 0.1, dodge.width = 0.2)
# Note that the grouping aesthetic and both col and fill set to "am":
wt.cyl.am <- ggplot(mtcars, aes(x = cyl, y = wt, col = am, fill = am, group = am))
wt.cyl.am + geom_point(position = dodge.posn)
# Plot summary statistics:
# Set the dodge position to only dodge:
dodge.posn <- position_dodge(.1)
# Plot mean 1SD
wt.cyl.am <- wt.cyl.am + stat_summary(fun.y = mean, geom = "point", position = dodge.posn)
#> Warning: `fun.y` is deprecated. Use `fun` instead.
wt.cyl.am +
stat_summary(fun.data = mean_sdl, geom = "errorbar", position = dodge.posn,
fun.args = list(mult = 1), width = 0.1)
# Plot the 95CI
wt.cyl.am +
stat_summary(fun.data = mean_cl_normal, geom = "errorbar", position = dodge.posn,
width = 0.1)
4.7 The Coordinates Layer
If you want to zoom in to show only a part of your plot, use the coord_cartesian(xlim=...) function. If you use xlim() or scale_x_continuous(), the non-plotted part of your data set will be removed, which is equivalent to plotting a sub-set of your data. This can have serious consequences for visual statistics, such as trend lines and density estimates. coord_cartesian() also allows you to remove extra margin spaces at the axis edges.
wt.disp <- ggplot(mtcars, aes(x = disp, y = wt)) + geom_point() + geom_smooth()
wt.disp # Default
#> `geom_smooth()` using method = 'loess' and formula 'y ~ x'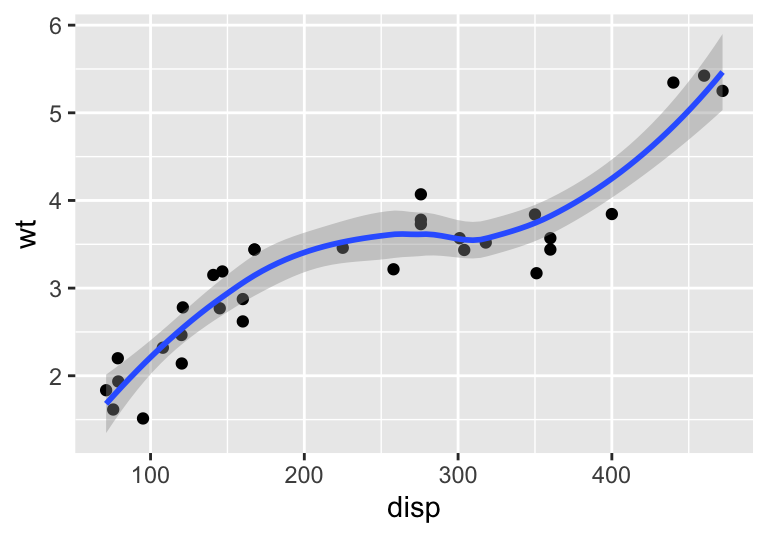
Figure 4.7: Using coord_cartesian to zoom-in on a plot
wt.disp + scale_x_continuous(limits = c(325, 500)) # limit x axis, center plot
#> `geom_smooth()` using method = 'loess' and formula 'y ~ x'
#> Warning: Removed 24 rows containing non-finite values
#> (stat_smooth).
#> Warning: Removed 24 rows containing missing values
#> (geom_point).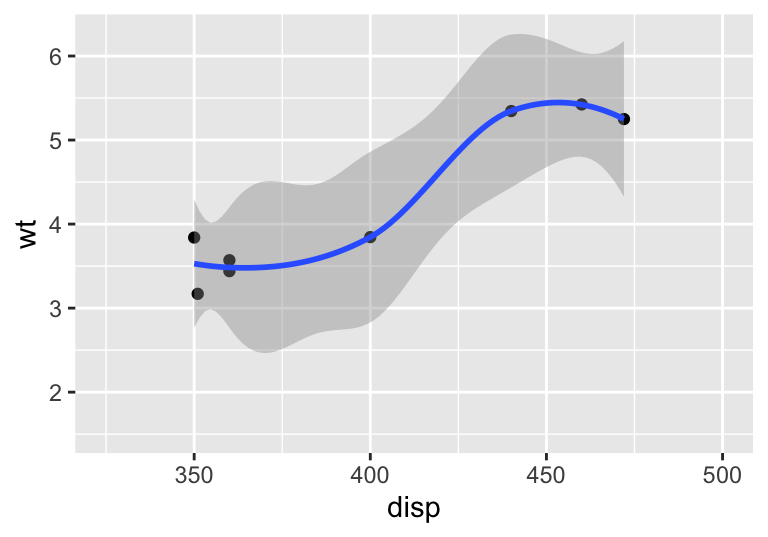
Figure 4.8: Using coord_cartesian to zoom-in on a plot
wt.disp + coord_cartesian(xlim = c(325, 500)) # zoomed-in, right plot
#> `geom_smooth()` using method = 'loess' and formula 'y ~ x'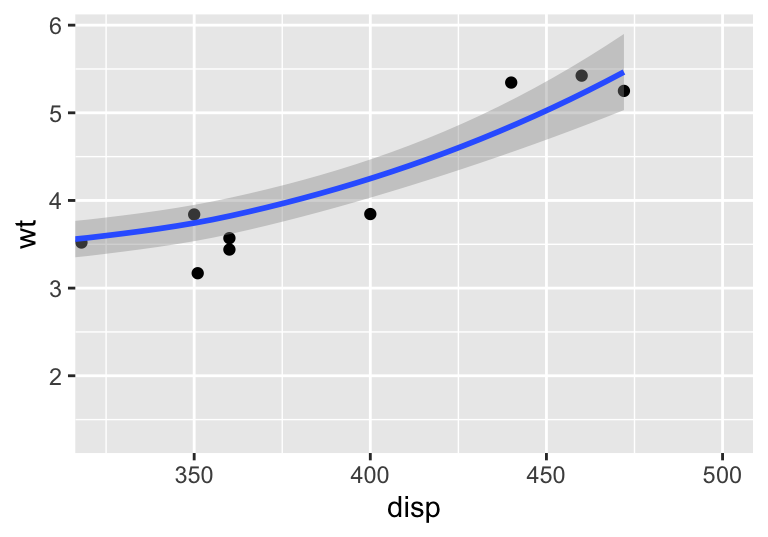
Figure 4.9: Using coord_cartesian to zoom-in on a plot
4.8 The Facets Layer
We can split the data layer into separate facets that can be on be individually processed later on. Note that the regression method is
only presented for the range of the data set, if you want a it to extend before and after, you can use the fullrange = TRUE argument.
mpg.wt <- ggplot(mtcars, aes(x = wt, y = mpg)) + facet_grid(. ~ cyl)
mpg.wt + stat_smooth(method = "lm") + geom_point()
#> `geom_smooth()` using formula 'y ~ x'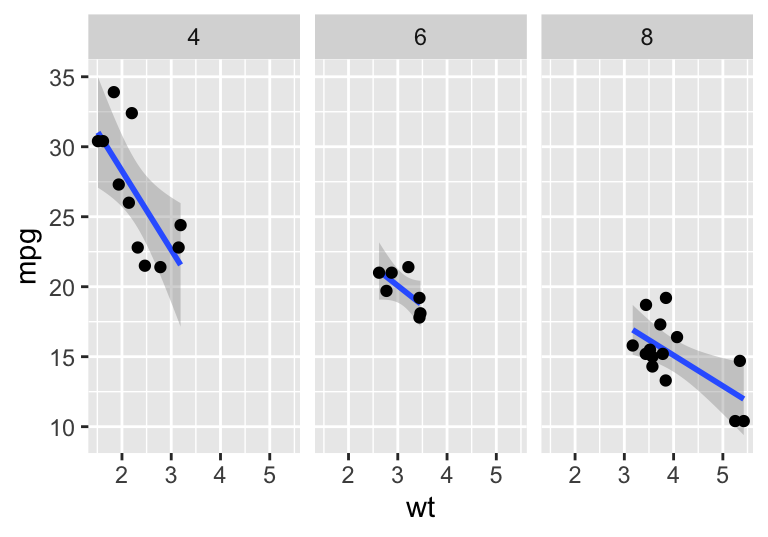
Figure 4.10: An example of faceting and smoothing with a ggplot.
mpg.wt + stat_smooth(method= "lm", fullrange = TRUE) + geom_point()
#> `geom_smooth()` using formula 'y ~ x'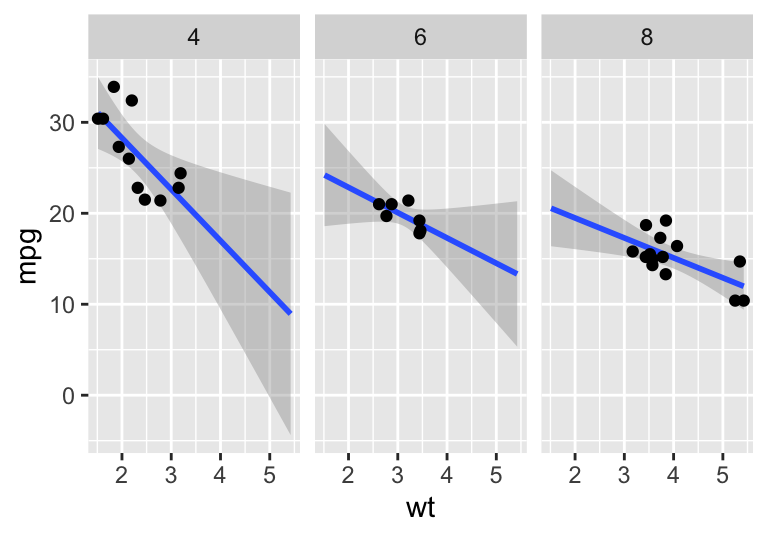
Figure 4.11: An example of faceting and smoothing with a ggplot.
Note the tilde notation in facet_grid(). Rows and columns are specified before and after the tilde, respectively. For example, . ~ cyl specifies no row separation and column separation according to the cyl factor.
An alternative to faceting in separate windows, is to sub-set the data according to a factor variable when the data layer is established. An example of this is shown at the top of the next page.
mpg.wt <- ggplot(mtcars, aes(x = wt, y = mpg, colour=factor(cyl)))
mpg.wt + stat_smooth(method= "lm") + geom_point()
#> `geom_smooth()` using formula 'y ~ x'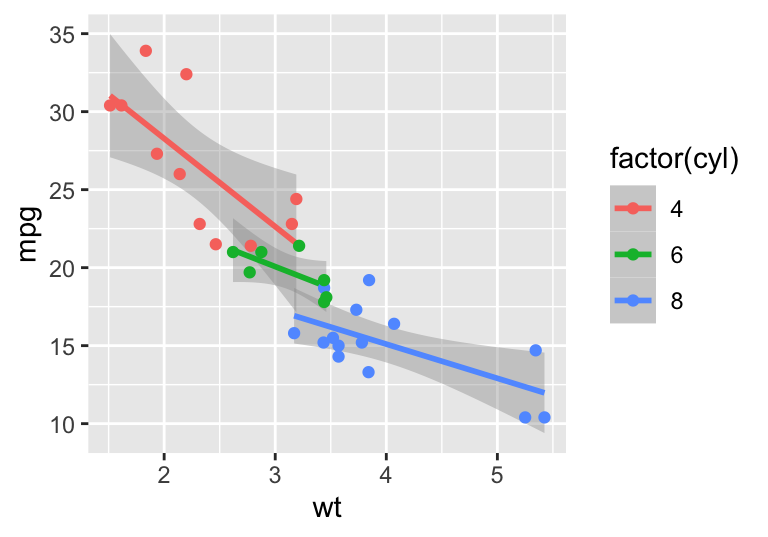
Figure 4.12: Sub-set by category
mpg.wt + stat_smooth(method= "lm", fullrange = TRUE, alpha = 0.1) + geom_point()
#> `geom_smooth()` using formula 'y ~ x'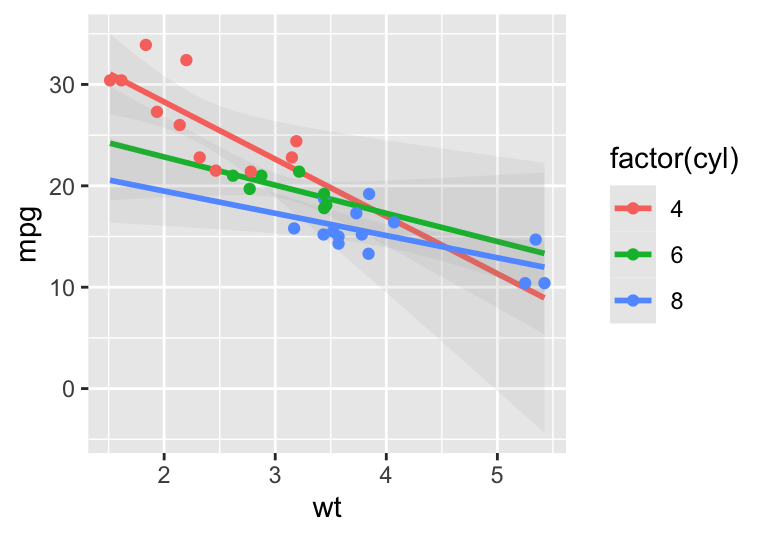
Figure 4.13: Sub-set by category
4.9 The Themes Layer
The last layer is the themes layer, but I’ll deal with this in detail in it’s own chapter 5.
4.10 Saving plots
If you are familiar with saving base package plots by opening and writing to a graphics device, you will need to wrap your entire ggplot() plot function in a print() call. To save plots, use the ggsave() function. This will automatically determine the file format (i.e. device) to use given the file name.